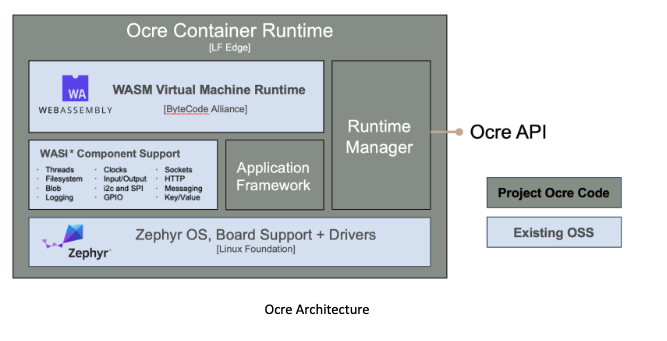
Written by Stephen Berard, Chief Technology Officer at Atym Introduction Highly constrained embedded systems play a pivotal role in modern technology, powering everything from consumer applications to industrial and critical…
The Zephyr Project will be on-site again at the embedded world Exhibition & Conference in Hall 4- booth 170. Demos: Analog Devices, Antmicro, Nordic Semiconductor and NXP as well as Ac6,…
This blog is written by Jonas Remmert, an IoT Embedded Systems Engineer at Phytec Messtechnik GmbH On April 9th, there is a workshop on the Zephyr Project at the Embedded…
A Preview of the upcoming Embedded World Conference talk by Oliver Völckers, Founder and Managing Director at BeST Berliner Sensortechnik GmbH As we anticipate our upcoming participation in the Embedded…
This blog, which originally ran on the Golioth Website, was written by Chris Wilson, the principal of Common Ground Electronics, a boutique embedded systems engineering services firm. For more content like…
This blog originally ran on the Antmicro website. For more Zephyr development tips and articles, please visit their blog. Neural networks are a powerful tool for processing noisy and unstructured sensor…
Yesterday, The Linux Foundation announced the keynote schedule for Open Source Summit North America, the premier event for open source code and community contributors. The leading gathering for the global open source…
On Friday, February 23, the Zephyr Project announced the 3.6 release. You can read about it here or watch the video here. In this special Zephyr Tech Talk on Wednesday,…
ROS 2 is a very popular open source robotics framework which allows to build and orchestrate very complex robotics systems. In this Zephyr Tech Talk video, Dave Rensberger, Principal Member…
Written by Mike Szczys, Developer Relations Engineer at Golioth and Zephyr Project Ambassador This blog originally ran on the Golioth website. For more content like this, click here. Embedded developers…