Mechanical keyboards have become increasingly popular, and keyboard enthusiasts all over the world are leveraging open source to build the perfect keyboard that does exactly what they want. ZMK is…
Zephyr RTOS is being used in a wide variety of applications where it is critical to be able to remotely observe and monitor the behavior of the device, in particular…
This blog originally ran on the Antmicro website. For more content like this, click here. Automotive engineering in the past 30 years has been transformed by the growing capabilities of microprocessors,…
There are many ways to implement inter-process communication (IPC) in Zephyr, and choosing the right one for your use case can be tricky. Are low-level kernel primitives to be preferred…
Earlier this month, thousands of attendees participated in Open Source Summit Japan to learn best practices, celebrate technology, discuss what’s next and network with each other. Kate Stewart, Vice President of Dependable…
Arduino UNO R4 is a super-nova in open hardware. This is cheap, readily available, and it can use many existing options from third parties and communities. We want to use…
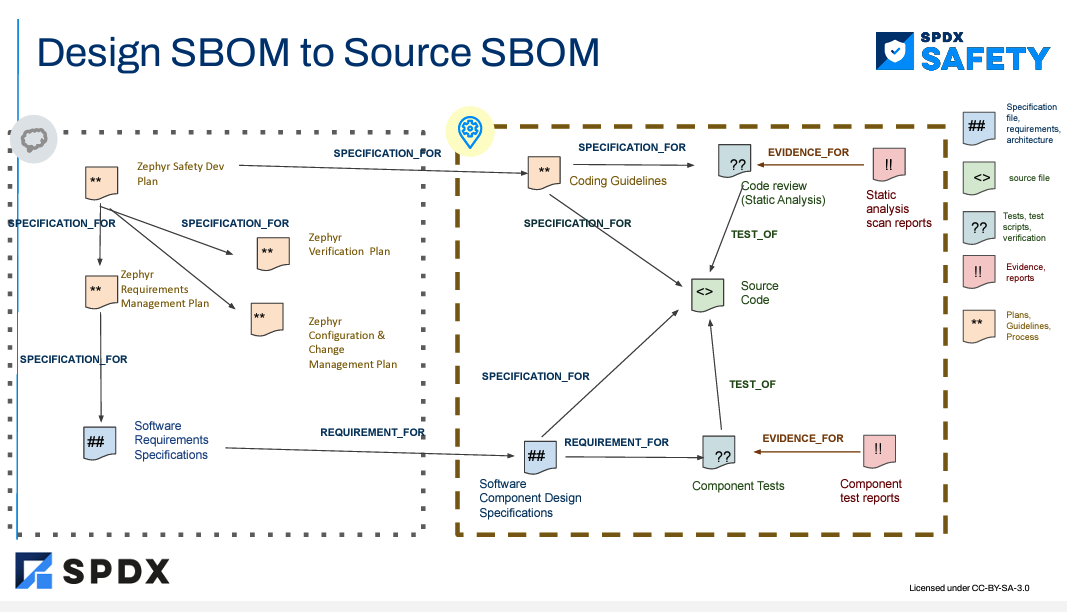
By looking at the press headlines, we’ve learned that open source is already being used in market segments (like space, automotive, industrial, medical, agricultural) applications that have safety considerations today. …
This blog originally ran on the LF Energy website. For more content like this, click here. Open Source Summit Europe 2023 brought together a panel of experts to explore the…
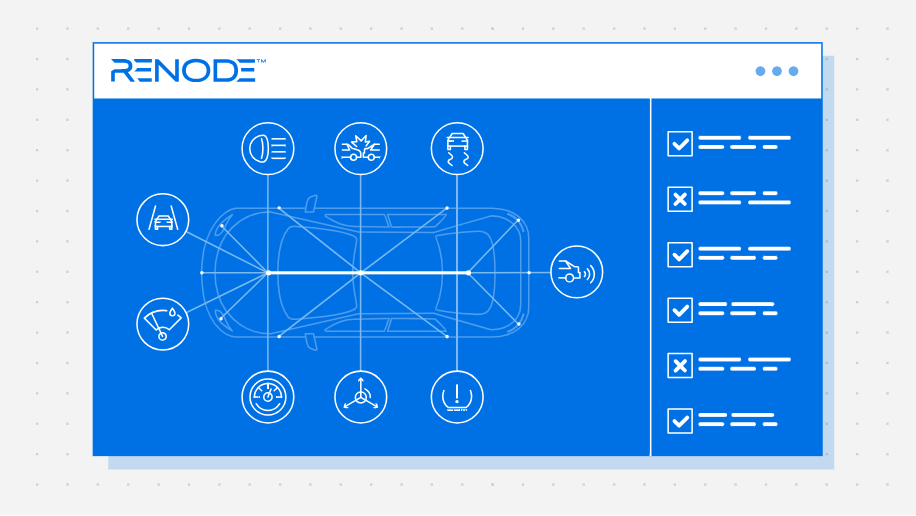
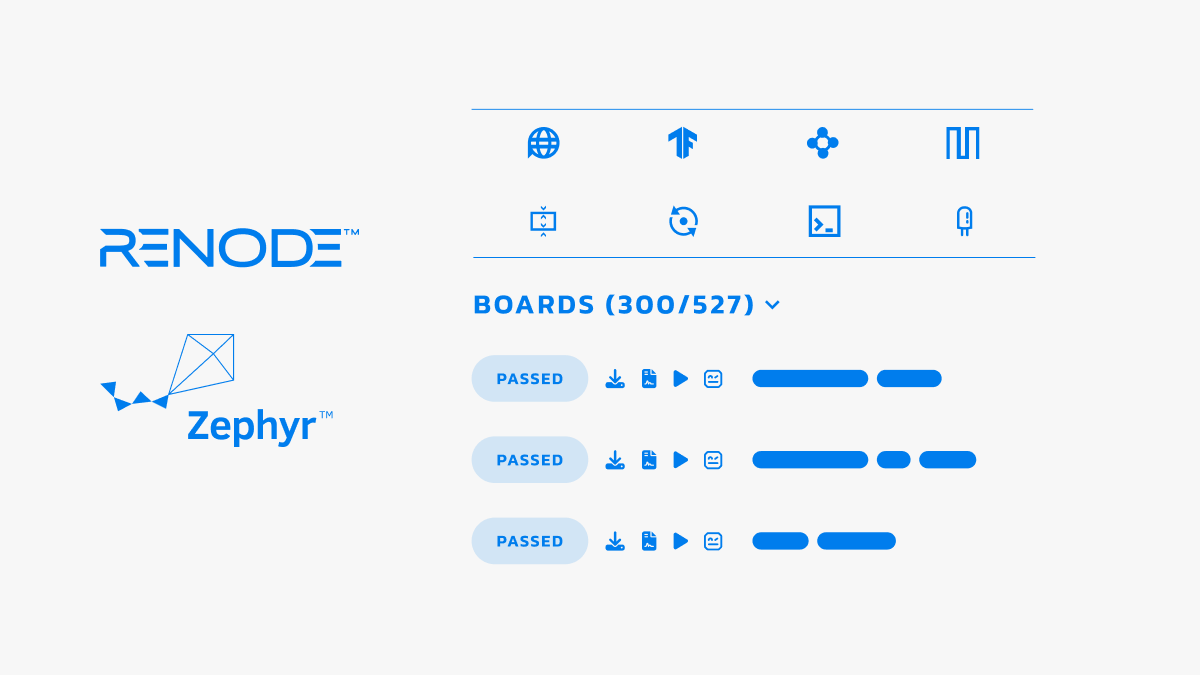
This blog originally ran on the Antmicro website. For more content like this, click here. Around two years ago, Antmicro introduced the Renode Zephyr Dashboard that combines structured data from the Zephyr RTOS with the capabilities of…
Written by Roy Jamil, Training Engineer at Ac6 Introduction Welcome to part 4 and the final part of our blog series on multithreading problems. In the previous articles ( part…