With more than 32,000 visitors from over 80 countries and over 1,100 exhibitors from almost 50 countries, embedded world 2024 has set another record! The Zephyr Project once again made…
The vibrant city of Berlin played host to the third Zephyr Project Meetup in Germany. The event kicked off with a warm welcome accompanied by refreshing drinks and delicious pizza,…
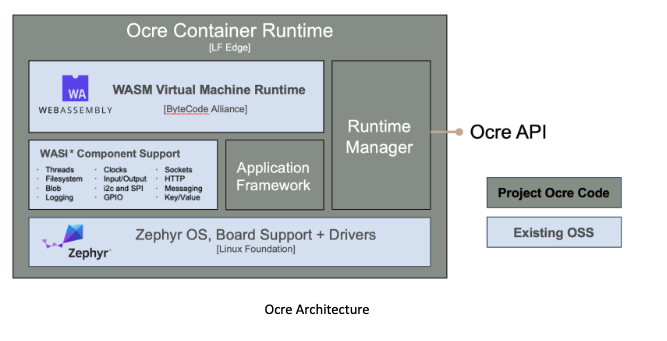
Written by Stephen Berard, Chief Technology Officer at Atym Introduction Highly constrained embedded systems play a pivotal role in modern technology, powering everything from consumer applications to industrial and critical…
The Zephyr Project will be on-site again at the embedded world Exhibition & Conference in Hall 4- booth 170. Demos: Analog Devices, Antmicro, Nordic Semiconductor and NXP as well as Ac6,…
Happy Friday! Welcome back for another edition of the Zephyr Weekly Update… with two weeks worth of news this time around In case you missed it, I highly recommend you…
Welcome to the third Zephyr Project Meetup in Germany! We're thrilled to host this meetup, and we invite you to join us tomorrow (April 5th, 2024) for an evening of…
This blog is written by Jonas Remmert, an IoT Embedded Systems Engineer at Phytec Messtechnik GmbH On April 9th, there is a workshop on the Zephyr Project at the Embedded…
A Preview of the upcoming Embedded World Conference talk by Oliver Völckers, Founder and Managing Director at BeST Berliner Sensortechnik GmbH As we anticipate our upcoming participation in the Embedded…
The embedded World Exhibition & Conference, occurring in Nuremberg, Germany from April 9-11, is a pivotal event for the global embedded community. Bringing together experts, industry leaders, and associations, it…
Welcome back for another weekly update about all things that happened in Zephyr land! Without further ado, let’s dive into the highlights of the past week. Using CLion for Zephyr…