

Inside the Zephyr Project Meetup in Copenhagen, Denmark
Inside the Zephyr Project Meetup in Copenhagen, Denmark
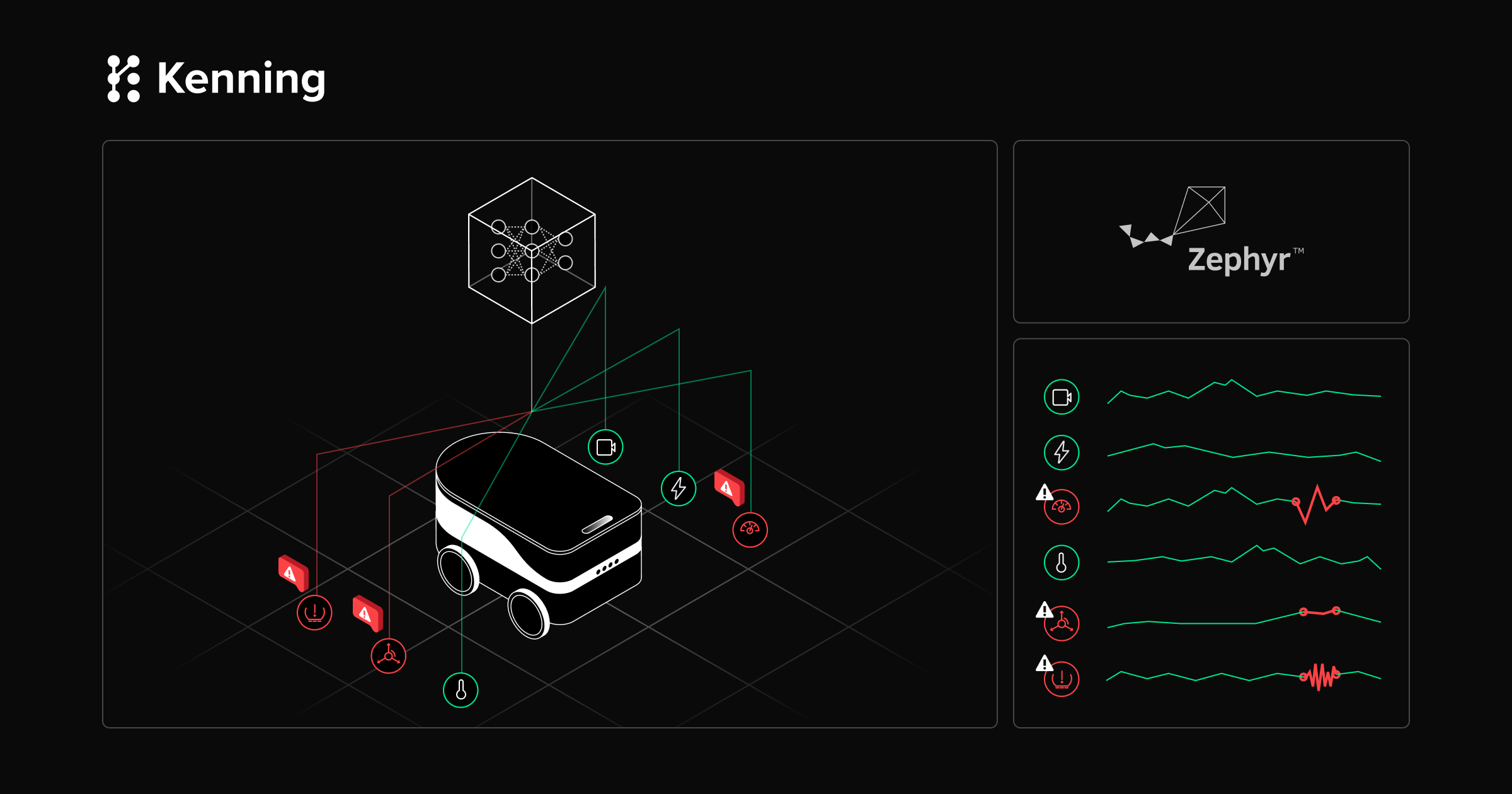
Anomaly detection in embedded devices using the Zephyr Sensor Anomalies library
Anomaly detection in embedded devices using the Zephyr Sensor Anomalies library

What to Expect at the Zephyr Project Meetup (June 30, 2026) in Lyon, France
What to Expect at the Zephyr Project Meetup (June 30, 2026) in Lyon, France

Recap: Zephyr Project Meetup – Kochi, Japan
Recap: Zephyr Project Meetup – Kochi, Japan

What to Expect at the Zephyr Project Meetup (June 25, 2026) in Austin, Texas
What to Expect at the Zephyr Project Meetup (June 25, 2026) in Austin, Texas

FIDO2 Comes to Zephyr — Zephyr Podcast #040
FIDO2 Comes to Zephyr — Zephyr Podcast #040

Zephyr’s 10-Year Milestone and the Road Ahead