Written by Roy Jamil, Training Engineer at Ac6
Welcome to part 2 of our blog series on multithreading problems. In the previous article, we discussed the fundamental concept of the producer-consumer problem and explored potential solutions using semaphores. If you haven’t had a chance to read it yet, we highly recommend checking it out for a comprehensive understanding.
In this part, we will delve into another solution for the producer-consumer problem by using a message queue. The producer(s)-consumer(s) problem revolves around coordinating multiple threads that share a common buffer for storing and retrieving data. By implementing a message queue, we can efficiently buffer the data produced by several producers and ensure seamless consumption by consumers.
In this series of 4 blogs, we’ll discuss some of the most common problems that can arise when working with multithreaded systems, and we’ll provide practical solutions for solving these problems:
From the producer-consumer problem, where multiple threads share a common buffer for storing and retrieving data, to the readers-writer problem, where multiple reader threads need to access a shared resource concurrently.
Used kernel features
To ensure a solid foundation for understanding the Producer(s)-Consumer(s) solution, we will begin by presenting the message queue mechanism.
A message queue (or msgq) is a mechanism that can hold a finite number of items of a specific size. It enables communication and synchronization between threads by allowing them to send and receive messages. When a thread puts a message into the queue, a copy of the data is stored in the msgq’s memory. Threads can block when putting or getting from the msgq, waiting for space or messages to become available. If the message queue becomes full and a timeout expires, data may be lost. Message queues are a useful mechanism for thread coordination and data sharing in concurrent programming.
If you’re interested in going deeper into mutual exclusion, synchronization, communication primitives, and other important concepts for developing robust multithreaded applications, check out our Zephyr training, or read this article.
Producer(s)-Consumer(s) problem
In the multiple producers and consumers’ problem, we face a new challenge compared to the single producer-consumer scenario: the need to ensure that data items generated by multiple producers are not overwritten or lost. With multiple producers concurrently adding items to a shared buffer or queue, and multiple consumers retrieving and processing these items, careful synchronization becomes crucial.
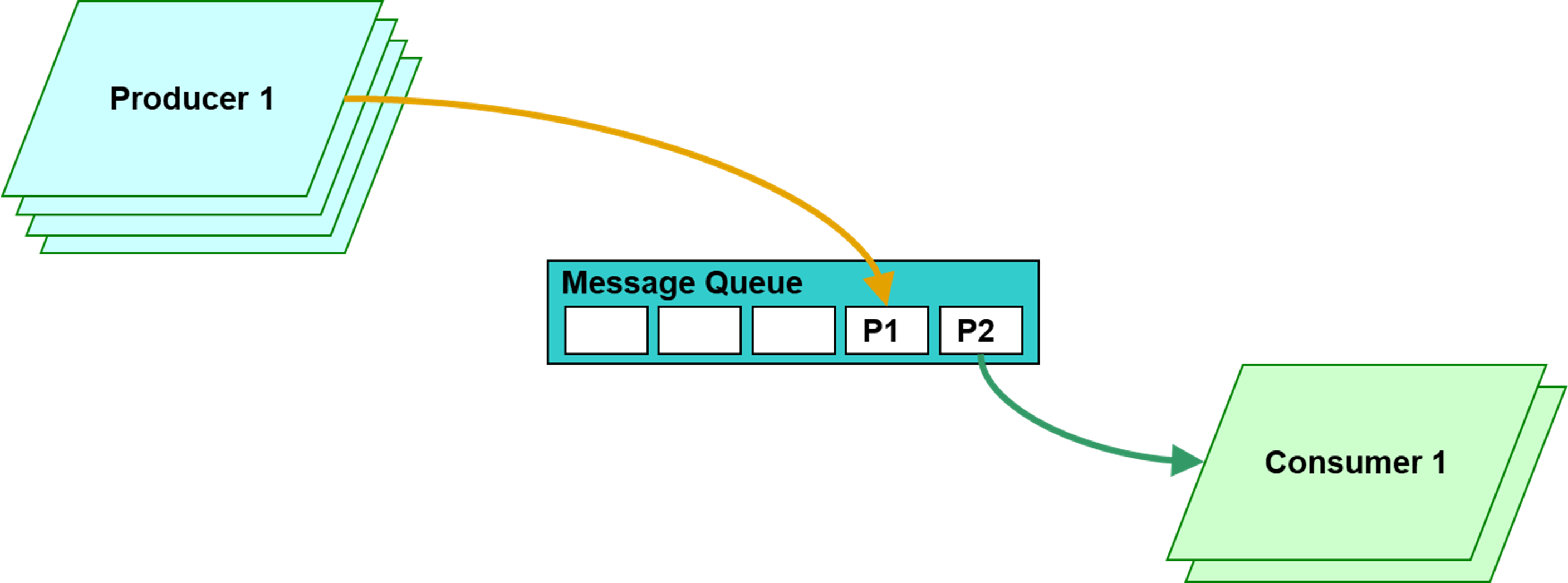
To solve the multiple producers-consumers’ problem, we can use the message queue for synchronization and for holding and passing the produced data to a consumer. The message queue ensures that data items produced by multiple producers are not overwritten or lost. When a producer wants to add an item to the queue, it uses the “put” operation. If the message queue is full, the producer will be blocked until space becomes available, ensuring that no data is lost. On the other hand, if a consumer executes first or there are no items in the queue, the consumer will be blocked when attempting to retrieve an item using the “get” operation. The consumer remains blocked until a producer adds an item to the queue, allowing the consumer to consume the data. This way, the message queue guarantees synchronization between producers and consumers, preventing data loss and ensuring communication and coordination between the threads involved.

In this code, we define an enumeration “sender” that represents the different producers (P1, P2, P3, P4). It also defines a structure “mydata” which contains the source (producer) and a token. A message queue that has a maximum capacity of “MAX_MESSAGES” and each message can hold a structure of type “mydata”.
The “Producer_entry” thread is responsible for generating data items “produced_data” and adding them to the message queue using “k_msgq_put”. The producer specifies its source (using the “_source” argument) and generates a token with “produce_token”.
The “Consumer_entry” thread retrieves items from the message queue using “k_msgq_get”. The consumer waits until there is a message in the queue (K_FOREVER timeout). Once a message is received, it extracts the token and the source (producer) information from the received data and prints them.
This code demonstrates how multiple producers can generate data items and add them to a message queue. The consumer thread retrieves these items from the queue and processes them. The message queue ensures synchronization and prevents data loss between the producers and consumers.
In addition to using message queues, there are alternative solutions. One such solution is utilizing the First-In-First-Out (FIFO) or Last-In-First-Out (LIFO) primitives or their underlying implementation the “Queue”. Queues have the advantage of being more flexible and can theoretically hold an infinite number of data items (limited by the available memory), but they typically require dynamic memory allocation. With a queue-based solution, the data is not copied to or from the queue.
However, it’s worth noting that the “Queue” mechanism introduces additional complexity compared to using message queues and typically requires more advanced memory management and dynamic allocation.
Trace and debug:
Tracealyzer can be used to help in understanding the behaviour of the system by providing a visual representation of how the different threads are interacting with each other over time. It can help to identify and diagnose problems such as deadlocks, priority inversions, and other synchronization issues by showing the order of execution and the flow of control between the different threads and tasks.
In this screenshot, we can see the execution pattern of the different threads and they have exactly received the event from the message queue to block or unblock them:
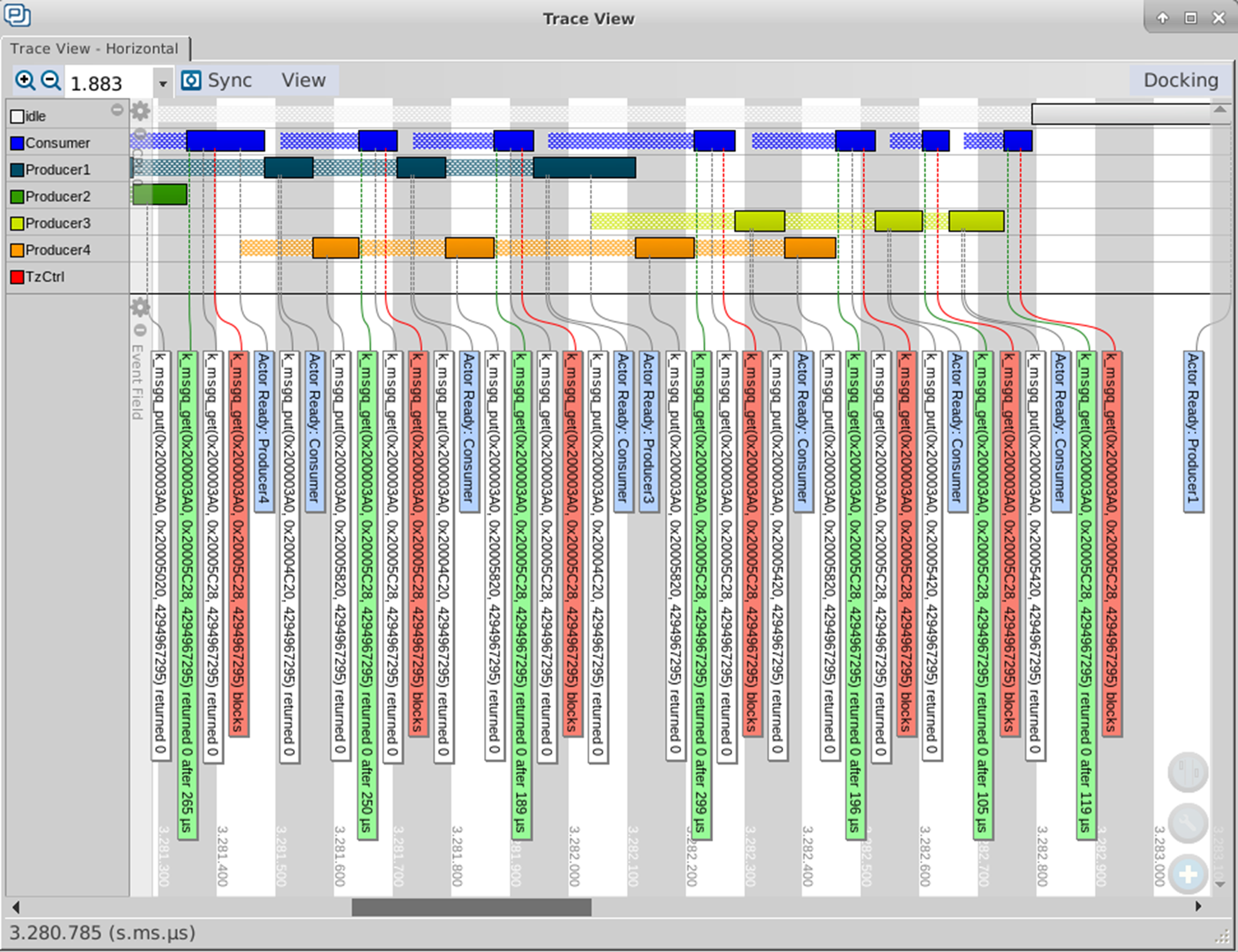
Figure 1-Execution pattern of the producers and consumer
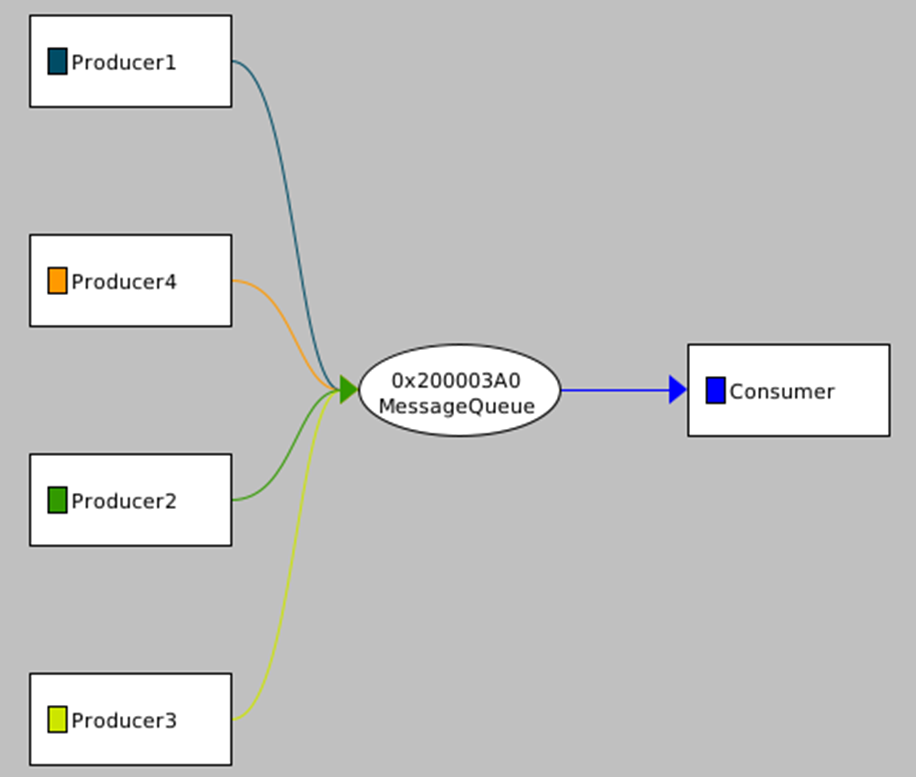
Figure 2-Communication flow
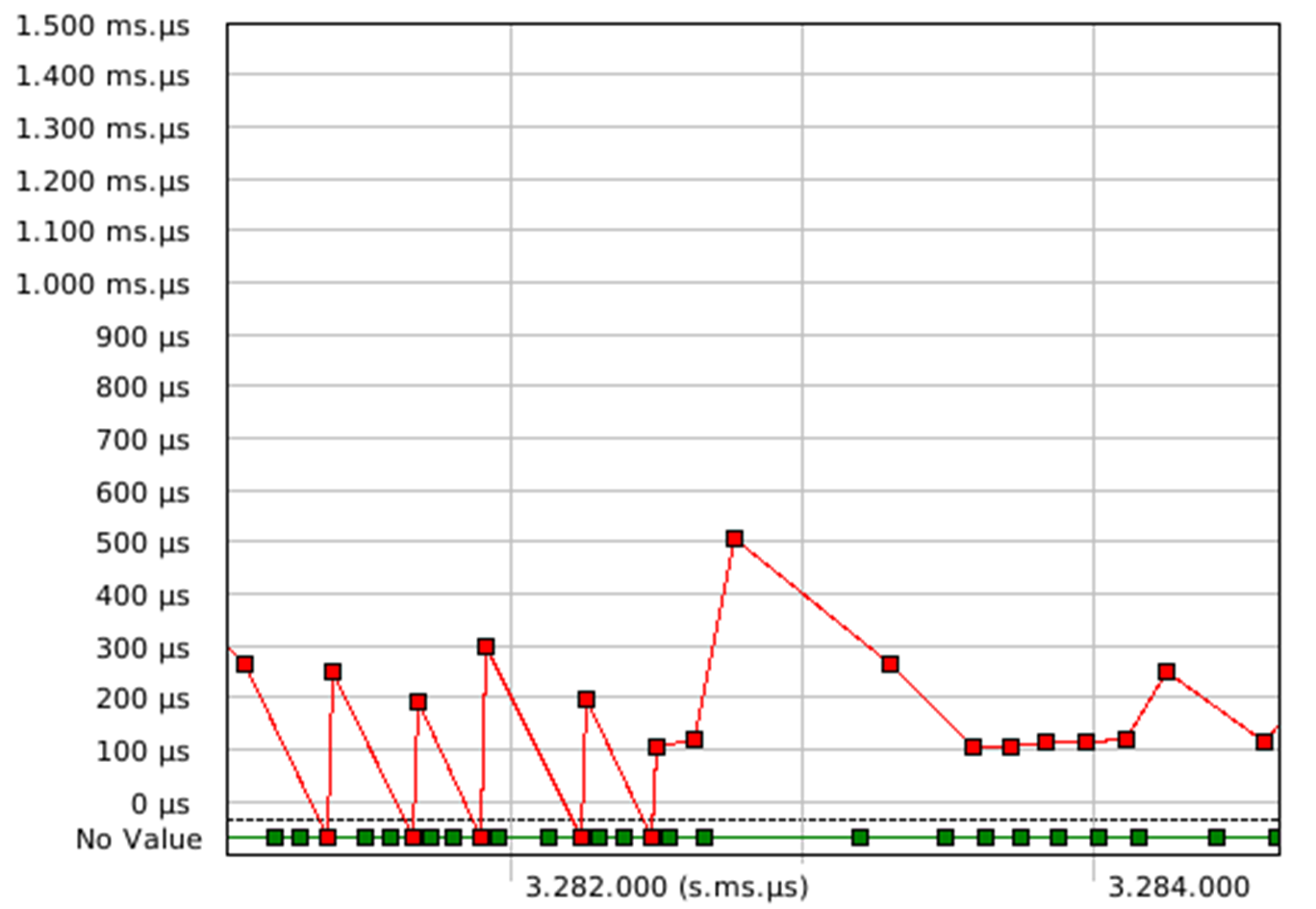 Figure 3-Service call block times by service
Figure 3-Service call block times by service
In the figure 2, we can see the communication flow to/from the message queue, in the figure 3 we can see the time spent by a thread in the blocked state waiting for the event, red dot is for the “k_msgq_get” called by the consumer and the green is for the “k_msgq_put” called by the different producers. We can notice that it has never been blocked on the “put” operation which means that producers have never attempted to put into a full message queue in this trace.
Conclusion
In conclusion, the message queue solution provides an effective mechanism for solving the multiple producers-consumers’ problem. It ensures synchronization between producers and consumers, preventing data loss and maintaining communication and coordination. The message queue guarantees that data items produced by multiple producers are not overwritten or lost, as producers are blocked when the queue is full, and consumers are blocked when the queue is empty. Additionally, Tracealyzer can be valuable in understanding the system’s behaviour by providing visual representations and insights into the execution pattern and communication flow between threads.
In the part 3 of this series, we are going to explain the readers-writer(s) problem and how to solve it.
If you’re interested in learning more about synchronization and communication mechanisms available in Zephyr, be sure to follow our full Zephyr training course. This course goes in-depth on the blocking and lock-free mechanisms available in Zephyr and covers a wide range of other multithreading problems and solutions. For more information, click here to see the course outline or register here: https://www.ac6-training.com/cours.php?ref=oRT5.