Written by Dr. Johan Kraft, CEO and founder of Percepio
When you have a task in your system that is supposed to execute at regular intervals, say for instance that it needs to read a sensor value every 5 milliseconds, then you have a system that is sensitive to random delays – also known as “jitter”. When your task experiences jitter, it sometimes has to wait more than its intended sleep time before next activation. Some minor jitter is hard to avoid and it seldom causes any problem, but excessive jitter is a different story.
The visible symptoms of (excessive) jitter can be very similar to what you see in a system that suffers from CPU starvation (LINK https://percepio.com/rtos-debug/cpu-starvation/), from general sluggishness to intermittent data loss or even malfunction. The fix is also similar: make sure you get the task priorities right and avoid long-running high-priority tasks.
Going into details, then: how do you best avoid jitter? The first thing is to make sure the RTOS is configured to use pre-emptive scheduling, so that the operating system is allowed to pre-empt the running task when higher priority tasks need to execute. And make sure that the RTOS tick rate – how often the RTOS timer interrupt occurs – is set high enough as this dictates how precise the system scheduler can be. Ideally, you want the time between two consecutive RTOS ticks to be much shorter than the period time of the most frequent tasks in the system, and ideally a common divisor of these periodicities. In practice, the RTOS tick rate can be a trade-off between real-time accuracy and RTOS processing overhead, as the RTOS tick uses up some processor cycles. On 32-bit systems this overhead is usually insignificant, but for slow 8-bit or 16-bit MCUs the effect can be more noticeable.
It is important that you never disable interrupts to protect a critical section in your code, as this disables the RTOS and with it the scheduling we have just discussed. Instead you should protect the critical section with a mutex or, even better, create a separate task to manage the resource you need to protect.
Accurate, pre-emptive RTOS scheduling is key to reducing jitter, but even with this in place you may experience some jitter. If you find that the disturbance comes from high priority tasks, you can consider changing the priorities. It may also be possible to nudge the starting times of the tasks involved in such a way that they no longer interfere with each other. A third option is to restructure the blocking task(s) to spend less time at high-priority level.
If you find that jitter is caused by an interrupt service routine (ISR), your best recourse is to try to reduce its execution time at interrupt level. This can be achieved e.g. by refactoring the code and move some of the processing to an ordinary task. One final option, if your task has very low jitter tolerance, is to refactor the task itself; its most time-critical parts can be implemented as an ISR that runs on a timer interrupt.
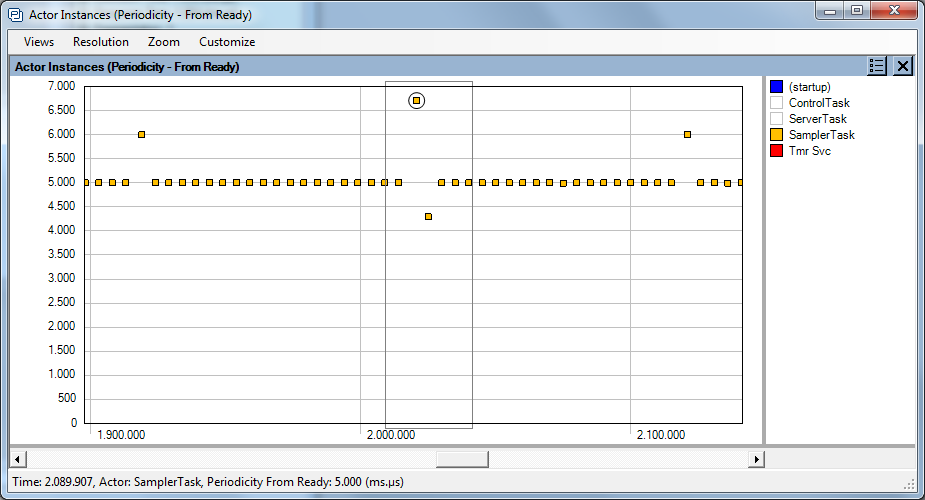
Tracealyzer can be quite helpful when it comes to locating jitter. In the diagram above, the X-axis is a timeline, and each point represents one execution of a particular task. The Y-value is time in milliseconds since the last execution. Normally we have 5 ms between task activations, but it is obvious from the plot that we have almost 7 ms at one point and also 6 ms on two occasions.
Why are these delays there? This diagram cannot answer that, but it provides pointers to places where we should trace execution in more detail to see what is going on.
This is part of a series from Zephyr Project member Percepio:
If you have any questions or comments, please feel free to reach out to the Zephyr community on the Zephyr Discord Channel.